Fixing 429 Too Many Requests on Solana: Why RPCs Fail
Getting rate limited on Solana? Learn why 429 errors happen, how RPC providers throttle requests, and infrastructure solutions that eliminate rate limits.


Getting rate limited on Solana? Learn why 429 errors happen, how RPC providers throttle requests, and infrastructure solutions that eliminate rate limits.
The Infrastructure Bottleneck
Operational disruptions in automated trading systems and decentralized applications may occur unexpectedly, independent of recent software deployments. A frequent manifestation of this instability is the emergence of 429 Too Many Requests errors, characterized by intermittent but persistent request failures.
{ "error": { "code": 429, "message": "Too Many Requests" } }
While standard troubleshooting procedures often involve investigating network status or implementing exponential backoff algorithms to address potential connection leaks, these measures frequently prove insufficient.
Evidence suggests that the source of these errors is rarely attributable to defects in the application code or the Solana blockchain protocol itself. Instead, the issue predominantly resides within the intermediary infrastructure layer facilitating network access. This guide analyzes the limitations inherent in standard service tiers, often described as the "Free Tier Illusion", and delineates infrastructure-level solutions requisite for ensuring consistent network throughput.
Section 1: What 429 Actually Means on Solana
When you see a 429 Too Many Requests error, it is crucial to understand where that error is generating from.
In cases where your subscription tier is insufficient for your traffic volume, you may encounter a specific rejection message indicating that your plan's limits have been exceeded.
In the broader context of Solana development, a 429 is almost never a protocol-level error. It is a gateway error. It means your RPC provider (Remote Procedure Call provider) has intercepted your request and decided not to forward it to the Solana cluster.
Think of your RPC provider as a bouncer at a club. The club (Solana) might have plenty of room, but the bouncer is refusing to let you in because you've tried to enter too many times in the last minute, or perhaps because the hallway is just too crowded with other people.
Crucially, this means your transaction or query never even reached the chain.
// This is NOT a Solana protocol error — it's your RPC provider rejecting you
try {
const balance = await connection.getBalance(pubkey);
} catch (e) {
if (e.message.includes('429')) {
// Stop debugging your smart contract.
// The Provider throttled you before the request even hit the wire.
console.error("Infrastructure throttling detected.");
}
}
If you are seeing this, you are being rate-limited at the infrastructure layer (Nginx, HAProxy, or custom middleware run by the provider), usually based on IP address or API key usage quotas.
Section 2: Why Free Tiers Throttle (The Economics of Shared Nodes)
To understand why you are being throttled, you have to follow the money.
Running a high-performance Solana node is expensive. It requires massive amounts of RAM (often 256GB+), fast NVMe storage, and significant bandwidth. To offer "free" tiers, RPC providers rely on oversubscription and virtualization.
The Shared Infrastructure Model
Most providers do not give you a dedicated machine. Instead, they run virtualized nodes on cloud giants like AWS or GCP. They then stack hundreds, sometimes thousands, of users onto the same backend infrastructure.
Imagine a single server handling requests for 100 different developers.
- User A is testing a basic wallet.
- User B is running a sniper bot scanning for new liquidity pools.
- User C (you) is trying to fetch a balance.
When User B's bot spikes in activity, it consumes the available CPU cycles and I/O operations of that shared node. The provider's load balancer detects the high load and instantly tightens the rate limits for everyone on that node to prevent a crash. You get a 429 error not because you did something wrong, but because your "noisy neighbor" is hogging the resources.
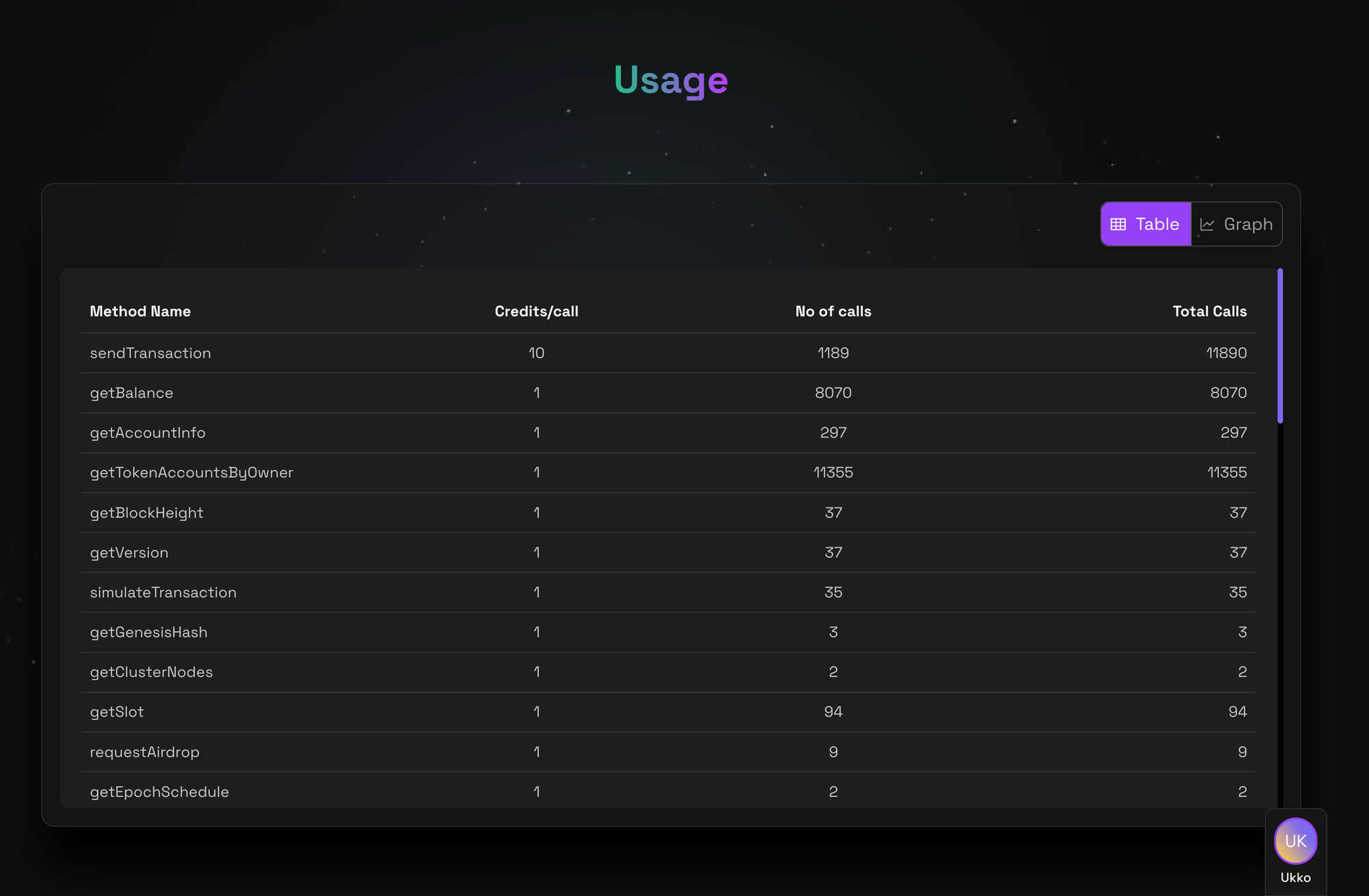
Understanding Credit Usage
Many providers manage these high-load environments using "Credit" systems. Instead of limiting you by a simple count of raw requests per second (RPS), they charge "credits" based on the computational weight of the method.
getSlot: Lightweight (1 credit)getProgramAccounts: Heavyweight (10 credits)
This system ensures fairness, complex network scans cost more than simple lookups. However, it means you need to be aware of the "weight" of your calls. A generous limit of 10 million credits can be exhausted quickly if you are running expensive methods in a loop without realizing their cost.
Peak Hour Degradation
The internet has tides. When the US markets open, or when a major NFT mint drops, traffic surges globally. Because free tiers often route through the cheapest, most congested data centers, your performance is strictly tied to global network congestion. 2:00 PM UTC (US morning) is a completely different reliability environment than 2:00 AM UTC.
Reality Check: Free tiers aren't designed for production. They are designed for "Hello World." They exist to get you integrated easily so you hit the paywall faster.
Section 3: The Methods That Trigger Throttling
Not all RPC calls are created equal. Some methods force the node to scan its entire ledger or index database, putting massive strain on the hardware. Providers often weight these calls higher to reflect their infrastructure cost.
RPC Method Cost Comparison
Method | Typical Credit Cost | Why It's Expensive |
| 1 | Simple memory lookup. Very fast. |
| 1 | Efficient batched lookup. |
| 1 | Simulation of transaction execution. |
| 10 | Requires processing and forwarding to the cluster. |
| 10 | Index scan. Forces the node to walk transaction history. |
| 10 | The Heavyweight. Scans account sets on the network. |
The Silent Killer: getProgramAccounts
The most common cause of sudden 429s is the misuse of getProgramAccounts (GPA). Developers often use this to find all token holders or all open orders.
// This looks innocent but hammers your RPC
const monitorTokens = async () => {
while (true) {
// DANGER: Each call here can cost 10x a standard request
// Doing this in a tight loop is the fastest way to get IP banned
const accounts = await connection.getProgramAccounts(TOKEN_PROGRAM_ID, {
filters: [{ dataSize: 165 }]
});
// Even with a 1s sleep, you are consuming ~864,000 credits/day
await sleep(1000);
}
};
If you run the code above on a free tier, you will likely be rate-limited within minutes. The provider sees you asking to scan massive amounts of account data every second and cuts you off to save the node.
Section 4: Common "Fixes" That Don't Work
When developers hit 429s, they usually try to fix it in code. These solutions are often just band-aids.
1. "Just Add Retry Logic"
You wrap your calls in a loop with exponential backoff.
- Why it fails: You are treating the symptom, not the disease. If the provider is throttling you because you're out of credits or the node is overloaded, waiting 200ms and trying again just delays the inevitable failure. It also adds massive latency to your application, which is fatal for trading bots.
2. Rotating Free Endpoints
You create an array of free endpoints (Solana Foundation, generic public nodes) and round-robin through them.
- Why it fails: Public endpoints are the "Wild West." They are even more throttled and congested than free tier provider keys. You are trading reliability for randomness.
3. Caching Responses
You cache the result of getAccountInfo for 30 seconds.
- Why it fails: This works for static data (like token metadata), but it is useless for real-time needs. A trading bot needs to know the exact balance and blockhash right now. Caching a blockhash makes your transactions fail with "Blockhash not found."
Section 5: What Actually Fixes 429s (Infrastructure-Level)
The only permanent fix for 429 errors is to change the environment your requests operate in. You need to move from a "noisy bus" to a "private car."
Dedicated RPC Endpoints
Moving to a dedicated node (or a high-tier shared node with strict reservations) means your requests are isolated. You are no longer competing with the NFT mint happening next door.
Bare-Metal vs. Cloud
This is a nuance few developers discuss. Most RPCs run on cloud instances (AWS/GCP). These instances suffer from hypervisor overhead, the virtualization layer that manages the cloud. Bare-metal infrastructure runs directly on physical servers. There is no virtualization layer. This eliminates CPU steal (where the cloud provider pauses your CPU to let another customer run) and offers significantly more consistent latency.
RPS vs. Credits
Usually providers uses combination of both Credits and RPS limits as opposed to credit-based allocation systems.
- Credit Model: Allocates a fixed pool of computational units (e.g., 10 million credits). This model often results in unpredictable service termination when complex queries exhaust quotas more rapidly than anticipated.
- RPS Model: Enforces a defined rate limit (e.g., 100 requests per second). This model offers predictability, allowing developers to implement precise client-side rate limiting to align with provider constraints.
Factor | Shared Cloud RPC | Bare-Metal Dedicated |
429 Risk | High (Shared limits, noisy neighbors) | Low (Your limits are yours alone) |
Peak Performance | Variable (Degrades during congestion) | Consistent |
Latency | Unpredictable (Cloud overhead) | Predictable (Physical hardware) |
Section 6: The Carbium Approach
The Carbium infrastructure was architected to address these specific reliability challenges. Diverging from the standard industry practice of reselling virtualized cloud instances, Carbium operates proprietary Swiss bare-metal infrastructure. By maintaining direct ownership and control of the physical servers, the platform eliminates virtualization overhead and the resource contention issues inherent in multi-tenant cloud environments.
For developers seeking to eliminate 429 errors, this structural difference offers four critical advantages:
- Transparent Limits & Low-Weight Credits: Carbium combines factual Requests Per Second (RPS) limits with a highly efficient credit model. While competitors often charge punitive rates (e.g., 100+ credits) for intensive operations like
getProgramAccounts, Carbium caps these at significantly lower values (e.g., 10 credits). This ensures your usage limits are defined by transparent benchmarks rather than inflated credit costs. - Resource Isolation: Control over physical hardware ensures that traffic spikes from other users do not impact the latency or reliability of your endpoint.
- Geographic Latency Optimization: Strategic placement of data centers in Switzerland affords sub-50ms latency for European traffic, avoiding the congestion frequently observed in US-based nodes.
- Integrated gRPC Support: Tiers above 320$ a month include access to gRPC streaming, enabling a transition from resource-intensive HTTP polling to efficient, push-based data delivery.
Focus on Application Logic, Not Infrastructure.

Section 7: Prevention Strategies (Actionable Takeaways)
Even with a dedicated provider, you should optimize your code to be a good citizen. Here is how to lower your RPC footprint:
1. Batch Your Requests
Don't send 10 separate HTTP requests. Send one.
// BAD: 10 network round-trips
for (let key of keys) {
await connection.getAccountInfo(key);
}
// GOOD: 1 network round-trip
const accounts = await connection.getMultipleAccountsInfo(keys);
2. Use WebSockets, Don't Poll
Polling is the enemy of efficiency. Instead of asking "Has this changed?" every second, open a socket and let the node tell you.
// BAD: Polling loop
setInterval(async () => {
const account = await connection.getAccountInfo(pubkey);
}, 1000);
// GOOD: WebSocket Subscription
connection.onAccountChange(pubkey, (accountInfo, context) => {
console.log("Account changed:", accountInfo);
});
3. Leverage gRPC Streaming (Best Market Value)
For high-frequency trading or real-time monitoring, standard HTTP polling is often the bottleneck. Transitioning to gRPC eliminates request overhead by establishing a persistent, push-based connection.
Carbium gRPC: The Competitive Edge Carbium offers the ecosystem's most accessible dedicated gRPC solution.
- Lowest Market Rate: Comprehensive gRPC access for $320/month—significantly more affordable than comparable enterprise tiers.
- Zero Latency: Direct push updates replace inefficient polling loops.
- Bare-Metal Reliability: Powered by Swiss infrastructure for maximum stability.
https://rpc.carbium.io